15 views
15 views
Problem Overview
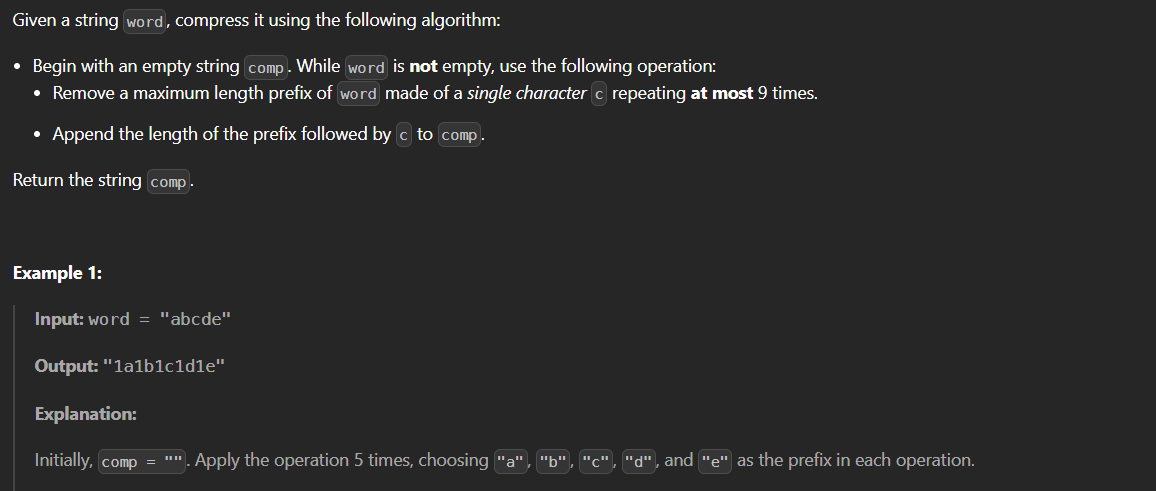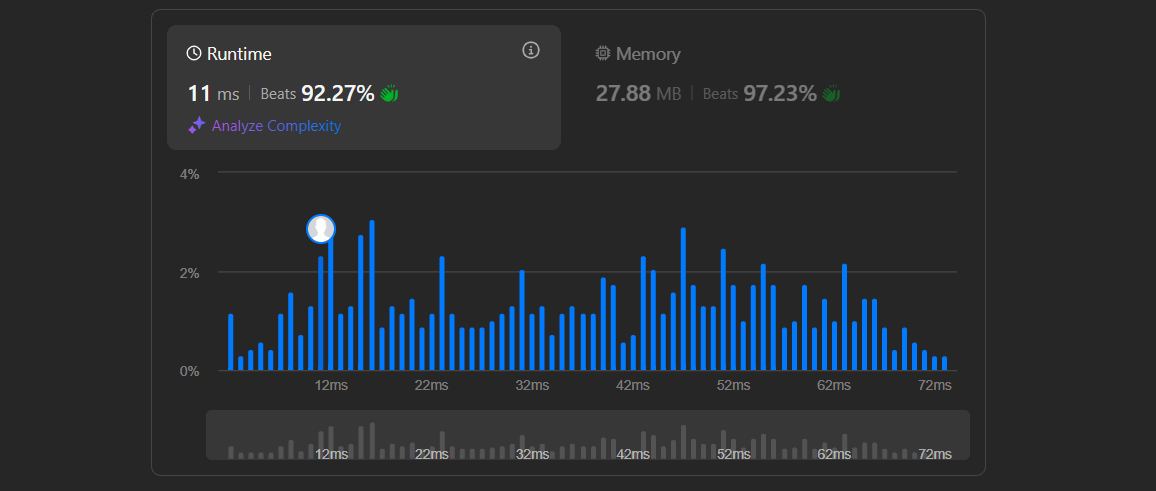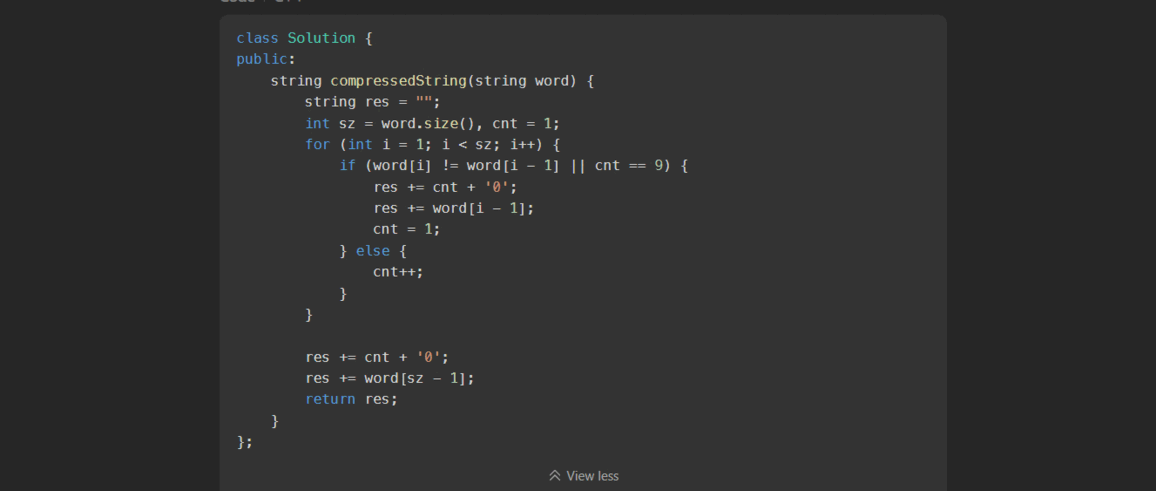
In LeetCode 3163: String Compression III, we are asked to compress a string by replacing consecutive repeated characters with a count followed by the character. One important detail is that the count cannot be greater than 9, so longer sequences need to be split properly.
For example, given the input "aaabbbcccc", we can compress it like this:
- 'a' occurs 3 times →
"3a" - 'b' occurs 3 times →
"3b" - 'c' occurs 4 times →
"4c"
So the final output becomes "3a3b4c".
The string will only contain lowercase English letters, and the goal is to compress it efficiently without exceeding the count limit of 9.
I found this problem interesting because it really makes you think about iterating through the string carefully and handling edge cases where the counts reach the maximum allowed.
Approach / Logic Explanation
My approach to this problem was to iterate through the string while keeping track of consecutive characters and their counts. The tricky part is making sure that the count never exceeds 9, which means sometimes I need to "split" a long sequence into multiple groups.
Here’s the step-by-step logic I followed:
- Initialize an empty string
resto store the compressed result and a countercntset to 1. - Start iterating from the second character (index 1) of the string.
- For each character:
- If it is the same as the previous character and the count is less than 9, increment
cnt. - If it is different from the previous character or
cntreaches 9, appendcntfollowed by the previous character toresand resetcntto 1.
- If it is the same as the previous character and the count is less than 9, increment
- After the loop ends, append the last counted character and its count to
res. - Return the final compressed string
res.
I also made sure to think about edge cases, such as strings with only one character or long sequences exceeding 9, to make sure my logic handles everything correctly.
Solution Code
Based on the logic I described, here’s the C++ solution I implemented for this problem:
class Solution {
public:
string compressedString(string word) {
string res = "";
int sz = word.size(), cnt = 1;
for (int i = 1; i < sz; i++) {
if (word[i] != word[i - 1] || cnt == 9) {
res += cnt + '0';
res += word[i - 1];
cnt = 1;
} else {
cnt++;
}
}
res += cnt + '0';
res += word[sz - 1];
return res;
}
};
I wrote this code carefully to handle both the cases where characters repeat less than 9 times and where they repeat more than 9 times. The cnt == 9 condition ensures that we never exceed the allowed count per group.
Step-by-Step Walkthrough
Let me explain how my code works using an example input: "aaabbbcccc".
- Initialization: Start with an empty string
res = ""and a countercnt = 1. - Iteration: Begin traversing the string from index 1:
- Compare each character with the previous one.
- If it matches and
cnt < 9, incrementcnt. - If it doesn't match or
cnt == 9, appendcnt + previous charactertoresand resetcnt = 1.
- Finalization: After the loop, append the last character and its count to
res.
For the input "aaabbbcccc":
- 'a' occurs 3 times → append "3a"
- 'b' occurs 3 times → append "3b"
- 'c' occurs 4 times → append "4c"
Final compressed string: "3a3b4c"
This step-by-step approach helped me ensure the code works for all edge cases, including sequences longer than 9 and strings with single characters.
Time & Space Complexity Analysis
After implementing the solution, I wanted to check how efficient it is:
Time Complexity
The code iterates through the string once, processing each character in constant time. Therefore, the time complexity is O(n), where n is the length of the input string.
Space Complexity
I use a separate string res to build the compressed result. In the worst case (no compression), res could be roughly the same length as the input, so the space complexity is O(n).
Overall, this solution is very efficient for strings of any reasonable length.
Mistakes to Avoid & Tips
cnt variable after appending a group to the result string. If you miss this, the count will carry over to the next character group.cnt++ in the wrong place can cause off-by-one errors in the output. Make sure you only increment when the character is the same as the previous one.9 for each run, even if there are more repeating characters. This keeps the compressed format valid and prevents issues with multi-digit counts.Sample Input & Output
To make it easier to understand, here’s a sample input and how the output looks after compression:
| Input | Compressed Output | Explanation |
|---|---|---|
| "aaabbbcccc" | "3a3b4c" | 'a' occurs 3 times → "3a" 'b' occurs 3 times → "3b" 'c' occurs 4 times → "4c" |
| "aaaaaaaaaa" | "9a1a" | Count cannot exceed 9, so sequence of 10 'a's is split into "9a1a". |
| "abc" | "1a1b1c" | No repeated characters, so each character is represented with count 1. |
Conclusion
Solving LeetCode 3163: String Compression III was a great exercise in string manipulation and careful iteration. It taught me to pay attention to edge cases, especially when sequences of characters exceed the maximum allowed count of 9.
The key takeaways from this problem are:
- Always handle edge cases like long sequences or single characters.
- Use a counter carefully and reset it at the right time.
- Think about time and space efficiency; this solution works in O(n) time.
I encourage you to try variations of this problem or explore the related string compression challenges. Practicing these problems will strengthen your understanding of string processing and algorithmic thinking.